Published:28/04/2026
Sovereign AI Architecture: Why Your Enterprise Data Should Never Leave the Building

Explore Sovereign AI architecture. Learn why enterprises are moving LLMs in-house to secure private VPCs, eliminate SaaS risks, and protect sensitive data.
Introduction: The Death of Data Trust
In the highly regulated corridors of Logistics, Finance, and Healthcare, traditional SaaS-based AI is transitioning from a competitive advantage to a strategic liability. As Large Language Models (LLMs) move from experimental chatbots to core operational engines — handling commercial contracts, medical records, and customs declarations — the traditional "trust me" model of cloud vendors is collapsing. Modern security demands a shift from "Trusting the Vendor" to "Owning the Component."
The architectural paradigm shift currently underway is the rise of Sovereign AI. As seen in the frameworks underpinning AutoConfirm and AutoFill, data sovereignty is no longer a marketing elective; it is a foundational architectural requirement. By treating AI as a self-hosted utility rather than a remote service, enterprises move beyond the "verify everything" bottleneck to a state of Data Content Sovereignty, where the "brain" of the AI resides within the client’s secure perimeter.
Core Philosophy: The Principle of Data Content Sovereignty
Data residency — merely knowing which jurisdiction holds your database — is a superficial solution to a deep architectural problem. True sovereignty requires that the processing "brain" (the LLM/STT engine) resides within the same secure perimeter as the data it consumes. To maintain intellectual honesty with SecOps teams, we define this as Data Content Sovereignty: a model where the content of your business intelligence remains strictly internal.
The following table contrasts the strategic risks of SaaS against the Sovereign model:
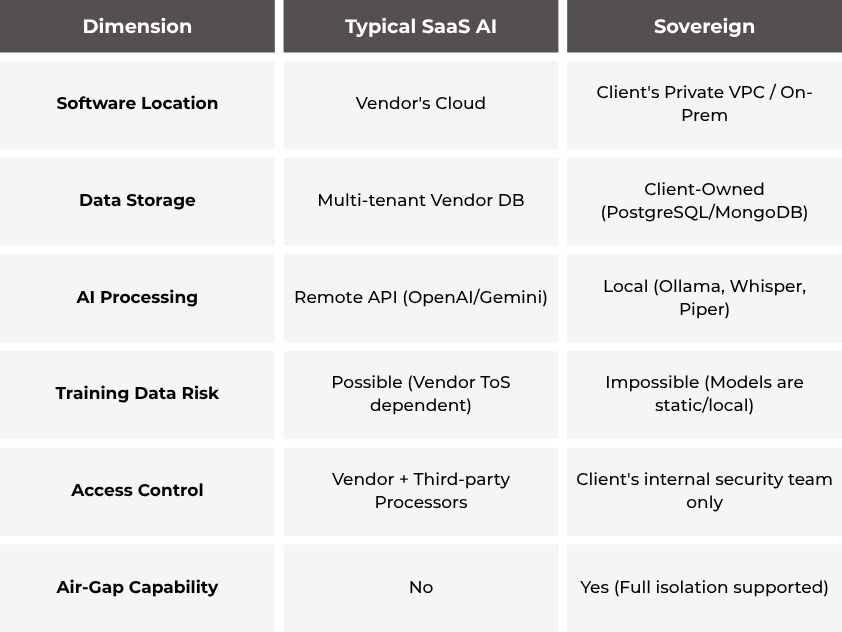
By keeping core data stores and inference engines within a private VPC, the vendor is technically and legally excluded from the data path. In this architecture, the AI is an internal utility.
Bringing the Brain Home: The Local AI Stack
The strategic breakthrough making Sovereign AI viable is the maturation of "Open-Weight" models. Running models like Qwen2.5, Mistral, or DeepSeek locally transforms AI from a leased service into a permanent asset.
The Technical Requirements
A production-grade local stack utilizes Ollama for LLM orchestration and Whisper for Speech-to-Text. However, a Senior Architect must be candid about hardware and scaling:
- The Latency Reality: For real-time voice interfaces (AutoConfirm), a GPU with 16GB+ VRAM (CUDA-supported) is a non-negotiable requirement. While 4–8GB of RAM may technically boot the software, it is insufficient for the sub-two-second latency required for human-to-AI conversation.
- Asynchronous Processing: For document-heavy tasks (AutoFill), CPU inference is a viable fallback, though GPU acceleration remains the recommended standard for high-volume throughput.
- Concurrency & Queuing: Because GPUs have hard VRAM limits, the architecture relies on strict internal queuing (via message brokers) to manage peak concurrency, ensuring that sudden spikes in document uploads or call volumes do not crash the inference engine.
Throwing hardware at an LLM isn't enough. If you get 50 concurrent calls, the system will crash without strict architectural queuing. We built this local stack to manage peak concurrency intelligently, ensuring your inference engine stays stable under pressure while eliminating the 'shadow training' risk. Your proprietary documents never become fodder for Big Tech's next foundation model.
Pavel Batashov, Chief Technology Officer at Twelvedevs
Architectural Fortresses: Security by Design
A "Headless" architecture (API-only) is inherently more secure for enterprise integration. By eliminating public-facing web UIs and session management, the attack surface is reduced to a single, stateless REST API integrated directly into your TMS, CRM, or ERP.
Isolation Patterns and Multi-Tenancy
We differentiate isolation based on the operational use case:
- Multi-tenancy via Domain Isolation (AutoConfirm): Designed for complex logistics networks, this model uses domainId foreign keys and UUID v7 identifiers to ensure mathematical isolation between business units, preventing data cross-contamination within a shared database.
- Single-tenant-by-design (AutoFill): For the highest tier of document privacy, each instance is deployed as a standalone containerized stack. This means a dedicated DB, dedicated API, and dedicated Ollama instance within its own network namespace. There is no shared storage, eliminating the risk of cross-tenant leaks via software vulnerabilities.
Furthermore, the code supports Air-gapped deployment, functioning in environments with no internet access — a critical requirement for government-grade security or highly sensitive customs operations.
The Shared Responsibility Model: Addressing the "Fine Print"
Technical integrity requires us to define the boundary between the software and the perimeter. Sovereignty is not a product you buy; it is a partnership you manage.
The SIP Paradox & Audio Data Lifecycle
While we maintain Data Content Sovereignty, we must acknowledge the "SIP Paradox." In voice automation, while the call transcript (the content) is processed locally, the SIP/RTP headers (metadata like phone numbers) must leave the perimeter to reach the telephony provider.
The Resolution: We treat the call as an "Envelope vs. Letter" scenario. The telephony provider sees the envelope (the SIP header) for routing, but the "letter" (the audio content) should be protected via SRTP and local STT processing to ensure the content remains private.
We treat voice data like radioactive material: process it and drop it. Once the audio reaches your local Whisper model, it’s transcribed in-memory and instantly destroyed. Unless your internal compliance strictly requires local archiving, the audio file never hits a hard drive.
Pavel Batashov, Chief Technology Officer at Twelvedevs
Client Responsibility
The software provides the tools for sovereignty, but the enterprise must provide the fortress. The client remains responsible for:
- Encryption: Implementing disk-level encryption (at-rest) and managing TLS 1.2+ termination.
- Perimeter Security: Managing VPC Security Groups, WAFs, and VPN access.
- Lifecycle Management: Maintaining backups and data retention policies within the PostgreSQL/MongoDB environment.
Compliance as a Side Effect, Not a Goal
In a Sovereign AI model, compliance is an architectural byproduct rather than an administrative burden. By eliminating the "Sub-processor" chain, the enterprise drastically reduces its Third-Party Risk Surface.
The Compliance-Ready Status
It is critical to note that while the architecture is designed for compliance, the current roadmap includes final-stage enterprise features like RBAC (Role-Based Access Control), JWT-authentication, and PII masking in logs. Therefore, we accurately categorize the current state as "Compliance-Ready."
- GDPR: Satisfied via data residency and CASCADE DELETE for the right to erasure.
- HIPAA: PHI remains isolated; no data is transmitted to external LLM APIs.
The "No-DPA Advantage" is the primary driver for legal teams. Because the vendor never touches the data, they are not a "Data Processor" in the legal sense, bypassing months of vendor due diligence and sub-processor audits.
Conclusion: The Rise of Autonomous Infrastructure
The future of enterprise AI lies in Autonomous Infrastructure. AI should be a utility the enterprise owns, not a service it leases at the whim of a cloud provider.
One of the most compelling arguments for this shift is the true Independence Factor: should the software vendor cease to exist, your self-hosted system remains fully operational. There are no "call home" mechanisms or remote license servers to shut down your business logic.
True vendor lock-in isn't about using a specific API; it's about who holds your data hostage. If we disappear tomorrow, you might eventually need to update your middleware routing, but you'll never have to fight to extract your data from our proprietary cloud. The system belongs to you, and it keeps running.
Pavel Batashov, Chief Technology Officer at Twelvedevs
As an architect, the question is no longer whether AI can solve your problems, but where its "brain" is located. In an age where data is your most valuable asset, can you afford to let your AI's brain live in someone else's cloud?



